Turbine
Turbine is an exceptional tool designed to streamline AI applications by automating the data pipeline process. It functions as a robust vector search engine that can seamlessly synchronize data from a
12,325
Votes
12,662
Views
7,368
Bookmarks
About
Turbine is an exceptional tool designed to streamline AI applications by automating the data pipeline process. It functions as a robust vector search engine that can seamlessly synchronize data from any database, ensuring it is ready for vector search. This tool is ideal for businesses that employ AI bots, as it allows them to harness the latest language models without the added stress of managing technical infrastructure. With Turbine, updates from your databases are reflected in real-time, abandoning the need for inefficient batch jobs, and utilizing advanced data engineering pipelines. Users are empowered to connect to multiple data sources like S3, PostgreSQL, and MongoDB, with a promise of expanding integrations. Additionally, Turbine supports popular embedding models and vector indexes from Pinecone, Milvus, OpenAI, and HuggingFace. The platform is engineered for high performance and scalability, accommodating various configurability options to tailor to specific needs, including data filters and embedding strategies. Ease of use is a cornerstone of Turbine, offering both a user-friendly console and a simple HTTP API for quick setups.
Key Features
- Real-time Database Sync: Turbine utilizes state-of-the-art data engineering pipelines that update your database changes instantaneously.
- Custom Embedding and Indexing: Provides the flexibility to use custom embedding models and vector indexes, with support for Pinecone, Milvus, OpenAI, and HuggingFace.
- Seamless Data Source Integration: Allows connection to multiple data sources like S3, PostgreSQL, and MongoDB, with additional integrations planned for the future.
- Configurable Pipeline Options: Offers endless configurability for your data pipeline, including filters, fields for embedding, and chunking strategies.
- Scalability and Speed: Engineered for high performance, using modern distributed stream-processing platforms to manage data efficiently.
FAQ
What is Turbine?
Turbine is a vector search engine that automates the process of syncing data from any database to prepare it for vector search, specifically designed to enhance AI applications.
Which data sources can I integrate with Turbine?
You can seamlessly integrate Turbine with data sources such as S3, PostgreSQL, and MongoDB, with more integrations coming soon.
Can I use my own embedding models and vector indexes with Turbine?
Yes, with Turbine, you can bring and use your own embedding models and vector indexes. It currently supports Pinecone, Milvus, OpenAI, and HuggingFace, with more to be added.
How does Turbine handle database changes?
Turbine ensures that database changes are synced in real-time, moving away from traditional batch jobs towards advanced data engineering pipelines for instant updates.
How quickly can I get started with Turbine?
Starting with Turbine is easy and fast. You can begin in under 2 minutes with a single HTTP POST request or use the intuitive UI of the Turbine Console for setup.
You may also like
More tools in Data & Analytics

Supametas.AI
A tool to transform unstructured data into structured formats for AI models and knowledge bases.
ZEN AI
Discover unparalleled customer service with ZEN AI, an intelligent customer support assistant designed for businesses of all sizes. ZEN AI operates around the clock, ensuring that your customers alway
Align AI
Streamlines AI strategy alignment with business objectives.

AICosts.ai
A tool to centralize tracking and optimization of spending across multiple AI services.

InstaSpeak
InstaSpeak is an innovative AI-powered Learning Management System designed specifically for enhancing spoken English skills. It provides a unique platform that integrates effortlessly with your Englis
RowSpeak
Turn messy spreadsheets into clear, ready reports.

Tagshop AI
A tool to generate video ads from prompts and assets.

Help Docs Generator
A tool to generate customer support help docs from SaaS product screenshots.
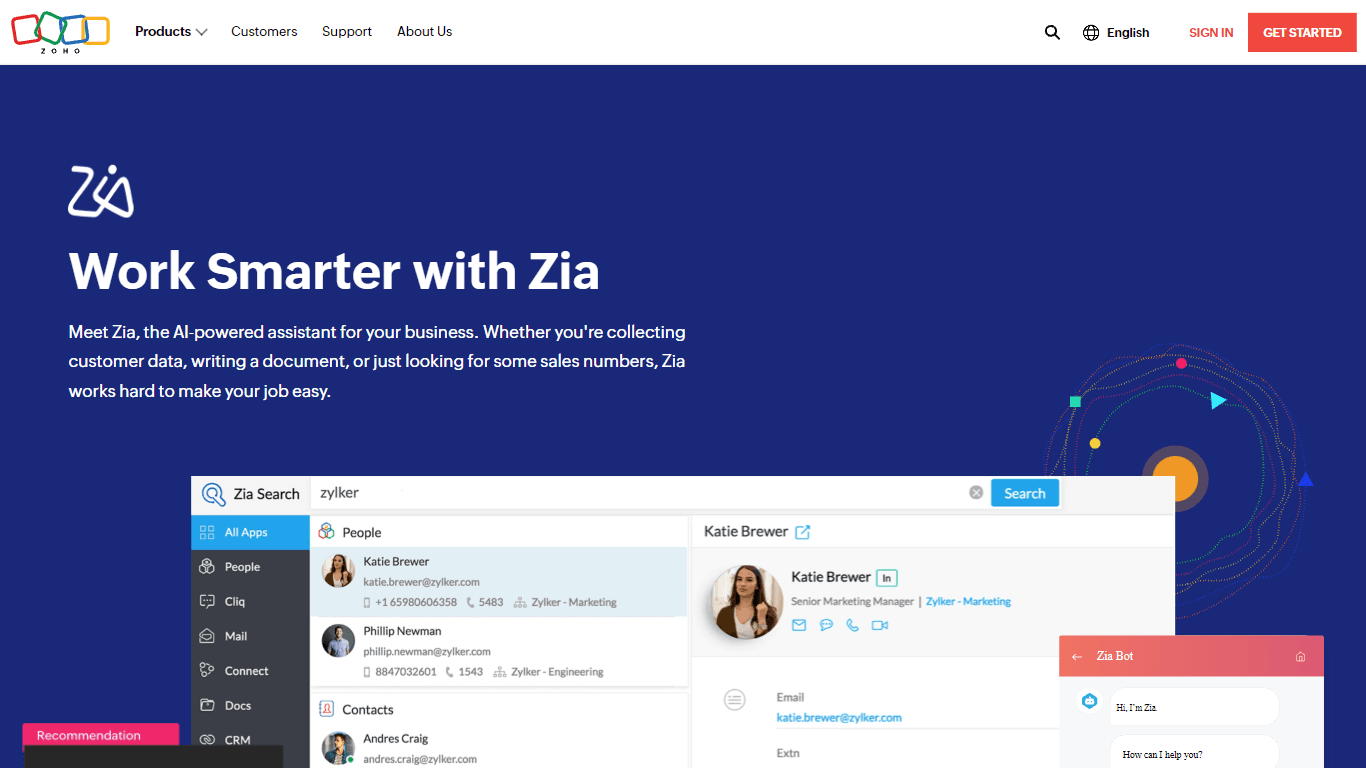
Zia
Maximize your business efficiency with Zia, Zoho's advanced AI assistant designed to streamline your business operations across various functions. Zia acts as a dynamic tool, providing tailored recomm

ZeroGPT
ZeroGPT.com stands out as the premier destination for AI detection, setting the gold standard in safeguarding digital landscapes. With cutting-edge algorithms and advanced machine learning models, Zer
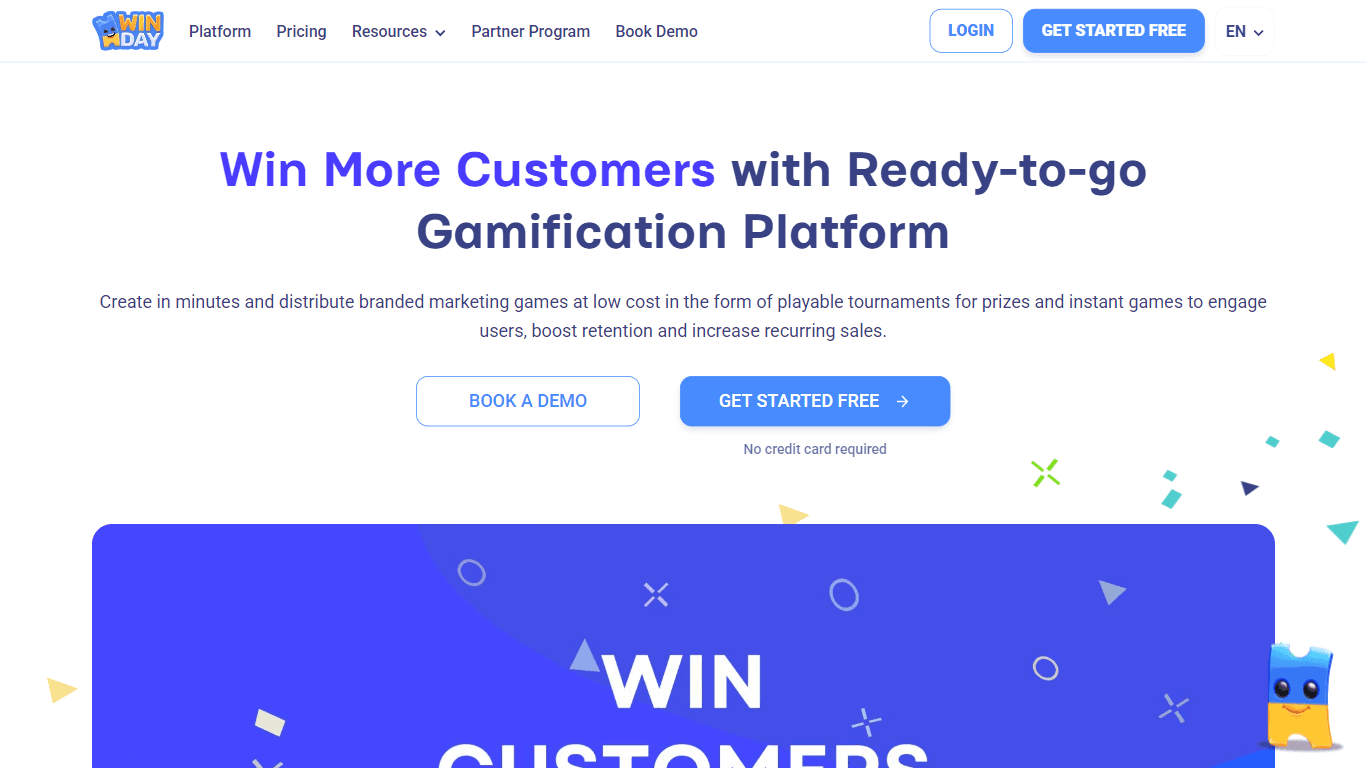
Winday
Winday is a no-code gamification platform that helps brands and creators design and launch branded marketing games quickly. It supports two main game types: Instant Games for quick coupon distribution

The North
North is an intuitive platform designed to simplify the management of Objectives and Key Results (OKRs), Strategy, and Initiatives for businesses of all sizes. It is a tool that directs teams to trans