
PaLM-E
The PaLM-E project introduces an innovative Embodied Multimodal Language Model, which integrates real-world sensor data with linguistic models for advanced robotic tasks. PaLM-E, short for "Projection
10,986
Votes
13,518
Views
5,431
Bookmarks
About
The PaLM-E project introduces an innovative Embodied Multimodal Language Model, which integrates real-world sensor data with linguistic models for advanced robotic tasks. PaLM-E, short for "Projection-based Language Model embodied," fuses textual inputs with continuous sensory information, such as visual and state estimation data, to create a comprehensive understanding and interaction in the physical world. Designed to aid in tasks like robotic manipulation planning, visual question answering, and captioning, PaLM-E showcases the potential of large, multimodal language models trained on varied tasks across domains. With its largest iteration, PaLM-E-562B, boasting 562 billion parameters, the model not only excels in robotic tasks but also achieves state-of-the-art performance in visual-language tasks like OK-VQA, while maintaining robust general language skills.
Key Features
- End-to-End Training: Integrates sensor modalities with text in multimodal sentences, training alongside a pre-trained large language model.
- Embodied Multimodal Capabilities: Addresses various real-world tasks, combining vision, language, and state estimation.
- Variety of Observation Modalities: Works with different types of sensor input, adapting to multiple robotic embodiments.
- Positive Transfer Learning: Benefits from training across diverse language and visual-language datasets.
- Scalability and Specialization: The PaLM-E-562B model specializes in visual-language performance while retaining broad language capabilities.
FAQ
What is the goal of the PaLM-E project?
The PaLM-E project aims to enable robots to understand and perform complex tasks by integrating real-world continuous sensor modalities with language models.
What is the achievement of the PaLM-E-562B model?
The PaLM-E-562B model, with 562 billion parameters, demonstrates state-of-the-art performance on visual-language tasks like OK-VQA while retaining versatile language abilities.
What does PaLM-E stand for?
PaLM-E stands for Projection-based Language Model Embodied, where PaLM refers to the pre-trained language model used.
Does PaLM-E benefit from transfer learning?
Yes, PaLM-E achieved positive transfer learning benefits by being trained across diverse internet-scale language, vision, and visual-language domains.
What tasks has PaLM-E been trained to perform?
Robotic manipulation planning, visual question answering, and captioning are some of the tasks that PaLM-E has been trained for.
You may also like
More tools in Other

SuperU AI
A nocode tool to create voice AI agents for customer communications.

@kuki_ai
Welcome to the world of Kuki, an award-winning artificial intelligence designed to bring entertainment to the digital age. Dive into engaging conversations with AI that's crafted to provide not just r

Integral Calculator - Wolfram|Alpha
The Integral Calculator provided by Wolfram|Alpha is a comprehensive tool designed for professionals, educators, students, and anyone with a need to solve complex mathematical integrals. By leveraging

LLM Council
A tool to compare and synthesize multiple LLM responses.

AptlyStar.AI
A tool to create and manage AI bots for businesses.

PureCode.ai
A tool to automate coding tasks through codebase-aware code generation.

AI Dungeon
AI Dungeon is a text-based adventure game where you lead the story and the AI creates the world around you. It offers endless possibilities by generating unique characters, settings, and scenarios bas

Verbacall
A platform that automatically answers, qualifies, and follows up on calls 24/7.

PrompTessor
A tool that optimizes text for clarity, tone, and grammar without requiring prompt engineering skills.

G3D.AI {Jedi}
G3D.AI {Jedi} is a generative AI tool for game creation that enables game creators to build beautiful and novel games in a fraction of the time. With a suite of tools designed to supercharge creativit
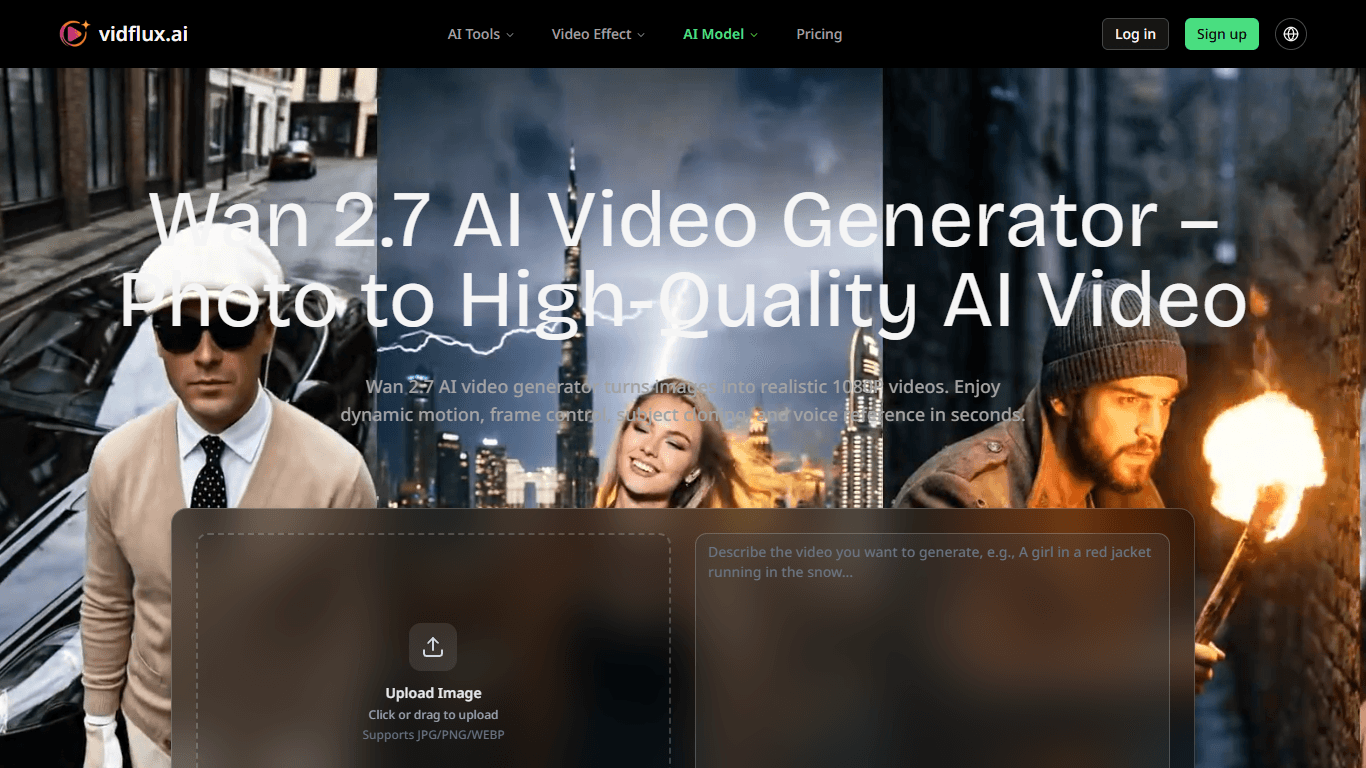
Wan 2.7 AI Video Generator
Wan 2.7 AI Video Generator transforms still images into high-quality, realistic 1080P videos with dynamic motion and advanced controls. It targets creators, marketers, e-commerce professionals, and di

Integral Calculator
**Integral Calculator by Studyx.ai: Your Advanced Guide to Mastering Calculus** The Integral Calculator, developed by studyx.ai, is an advanced GPT-based tool designed to enhance the learning experie